假阳性与假阴性
简介
准确预测与不准确预测的比率绘制在一个称为混淆矩阵的矩阵中。这指的是二元分类器的真阴性和真阳性(正确预测)与假阴性和假阳性(错误预测)的比率。在数据清理、预处理和解析之后,我们要做的第一件事就是将数据输入到一个有效的模型中,该模型自然会产生概率结果。不过请稍等!但我们如何评估模型的性能?
更高的性能,更好的效率——这正是我们想要的。这时,混淆矩阵就派上用场了。机器学习分类的过程评估就是混淆矩阵。本文将介绍假阳性和假阴性之间的区别。
混淆矩阵
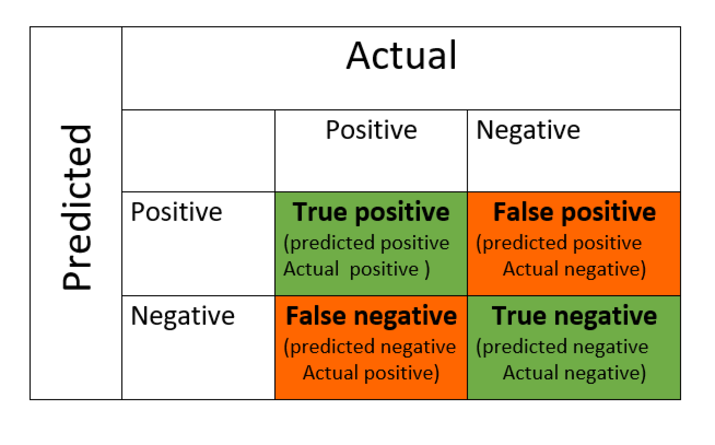
它是使用机器学习进行分类问题的性能指标,其输出可以是两个甚至更多的类别。表中有四种可能的预测值和实际值组合。
与混淆矩阵相关的术语有 −
真阳性 − 实际值和预测值均为正的情况。
真阴性 − 实际值和预测值均为负的情况。
假阳性 − 实际值为负,预测值为正的情况。
假阴性 − 实际值为正,预测值为负的情况。
混淆矩阵的格式如下 −
让我们看一个例子 -
假设,我们想弄清楚血癌测试能多好地预测患者的感染状态。这里的冠状病毒测试用于区分两种可能的状态:感染和正常。
真阳性 - 分类器表明该人已被感染,第二次癌症测试证实了这一发现。结果,测试是正确的。
假阳性 - 一个人的初步测试结果为阳性,但随后的 PCR 测试显示该人确实是阴性,没有感染。
真阴性 - 分类器将快速测试分类为阴性,而该人实际上并未感染。
假阴性 - 分类器将快速测试分类为阳性,但该人实际上已被感染且不健康,因此测试应为阴性。
假阳性和假阴性之间的区别
以下是假阳性和假阴性之间的一些主要区别 -
假阳性 |
假阴性 |
|---|---|
实际值为负,预测值为正的情况 |
实际值为正,预测值为负的情况。 |
也称为"I 类错误" |
也称为"II 类错误" |
具有两个类 True 和 False 的二元分类示例可以让您理解这一点。假阳性值是那些被认为属于"真"类的值,而实际上它们不属于,而是属于"假"类。 |
具有两个类 True 和 False 的二元分类场景可以让您理解这一点。假阴性值是那些被认为属于"假类别"但实际上属于"真类别"的值。 |
这显示了分类器错误预测期望结果的频率。 |
此错误显示了分类器错误预测不利结果的频率。 |
假阳性率,也称为误差,可以定义为假阳性与假阳性和真阴性之和的比率 |
假阴性与假阴性和真阳性之和的比率称为假阴性率,通常称为漏检率率 |
一封非垃圾邮件被错误地识别为垃圾邮件。 |
一封垃圾邮件被错误地识别为非垃圾邮件。 |
结论
在本文中,我们了解了假阳性和假阴性之间的区别。我们如何评估机器学习模型将决定它们是成功还是失败。为了公平地评估模型的性能,彻底的模型分析是必要的。
我们已经研究了如何使用混淆矩阵来检查机器学习分类器或模型是否正确预测了值以及模型的准确性。因此,混淆矩阵有助于分类器的评估。它包含四个字段,分别是真阳性、真阴性、假阳性、假阴性。


