Apache Spark - RDD
弹性分布式数据集
弹性分布式数据集 (RDD) 是 Spark 的基本数据结构。 它是一个不可变的分布式对象集合。 RDD 中的每个数据集都被划分为逻辑分区,可以在集群的不同节点上进行计算。 RDD 可以包含任何类型的 Python、Java 或 Scala 对象,包括用户定义的类。
形式上,RDD 是一个只读的、分区的记录集合。 可以通过对稳定存储上的数据或其他 RDD 上的数据进行确定性操作来创建 RDD。 RDD 是可以并行操作的元素的容错集合。
创建 RDD 有两种方法 − 并行化驱动程序中的现有集合,或引用数据集外部存储系统,例如共享文件系统、HDFS、HBase 或任何提供 Hadoop 输入格式。
Spark 利用 RDD 的概念来实现更快、更高效的 MapReduce 操作。 让我们首先讨论 MapReduce 操作是如何发生的以及为什么它们没有那么高效。
MapReduce 中的数据共享很慢
MapReduce 被广泛用于通过集群上的并行分布式算法处理和生成大型数据集。 它允许用户使用一组高级运算符编写并行计算,而不必担心工作分配和容错。
不幸的是,在大多数当前框架中,在计算之间(例如在两个 MapReduce 作业之间重用数据)的唯一方法是将其写入外部稳定存储系统(例如在 HDFS 之间)。尽管该框架为访问集群的计算资源提供了许多抽象,但用户仍然需要更多。
Iterative 和 Interactive 应用程序都需要更快地跨并行作业共享数据。 由于复制、序列化和磁盘 IO,MapReduce 中的数据共享速度很慢。在存储系统方面,大部分的 Hadoop 应用,在 HDFS 读写操作上花费的时间都超过了一个 90% 。
MapReduce 上的迭代操作
在多阶段应用程序的多个计算中重用中间结果。 下图解释了当前框架是如何工作的,同时在 MapReduce 上进行迭代操作。 由于数据复制、磁盘 I/O 和序列化,这会产生大量开销,从而使系统变慢。
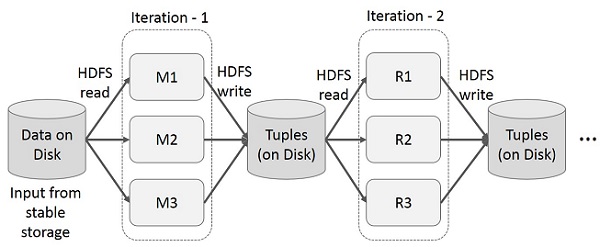
MapReduce 上的交互操作
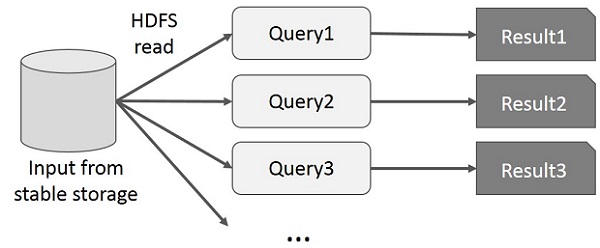
用户对同一数据子集运行临时查询。 每个查询都会在稳定存储上进行磁盘 I/O,这会支配应用程序的执行时间。
下图解释了当前框架在 MapReduce 上进行交互式查询时的工作原理。
使用 Spark RDD 进行数据共享
由于复制、序列化和磁盘 IO,MapReduce 中的数据共享速度很慢。 大多数 Hadoop 应用程序,90% 以上的时间都花在了 HDFS 的读写操作上。
认识到这个问题,研究人员开发了一个名为 Apache Spark 的专门框架。 spark的核心思想是Resilient Distributed Datasets (RDD);它支持内存处理计算。 这意味着,它将内存状态存储为跨作业的对象,并且该对象在这些作业之间是可共享的。 内存中的数据共享比网络和磁盘快 10 到 100 倍。
现在让我们尝试找出在 Spark RDD 中迭代和交互操作是如何发生的。
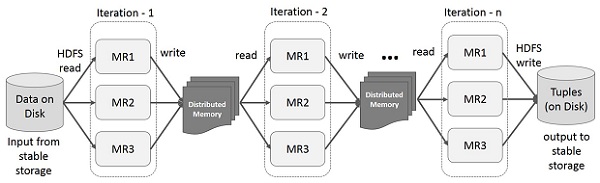
Spark RDD 上的迭代操作/h2>
下图展示了 Spark RDD 上的迭代操作。 它将中间结果存储在分布式内存而不是稳定存储(磁盘)中,并使系统更快。
注意 − 如果分布式内存 (RAM) 不足以存储中间结果(作业状态),那么它将把这些结果存储在磁盘上。
Spark RDD 上的交互操作
此图显示了 Spark RDD 上的交互式操作。 如果对同一组数据重复运行不同的查询,则可以将这些特定数据保存在内存中以缩短执行时间。
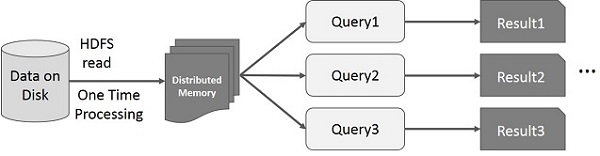
默认情况下,每个转换后的 RDD 可能会在您每次对其运行操作时重新计算。 但是,您也可以在内存中持久化 RDD,在这种情况下,Spark 会将元素保留在集群上,以便在下次查询时更快地访问它。 还支持在磁盘上持久化 RDD,或跨多个节点复制。


