Seaborn - 绘制分类数据
在我们之前的章节中,我们学习了散点图、hexbin 图和 kde 图,它们用于分析所研究的连续变量。 当研究的变量是分类变量时,这些图不适用。
当所研究的一个或两个变量是分类变量时,我们使用 striplot()、swarmplot() 等图。 Seaborn 提供了这样做的接口。
分类散点图
在本节中,我们将学习分类散点图。
stripplot()
当研究的变量之一是分类变量时,使用 stripplot()。 它表示沿任何一个轴排序的数据。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df)
plt.show()
输出
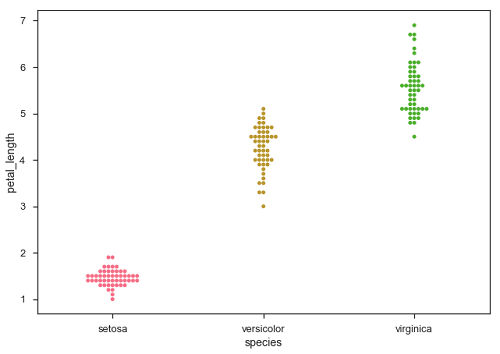
在上面的图中,我们可以清楚地看到每个物种的 petal_length 的差异。 但是,上述散点图的主要问题是散点图上的点重叠。 我们使用"Jitter"参数来处理这种情况。
Jitter(抖动)给数据增加了一些随机噪声。 此参数将调整沿分类轴的位置。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()
输出
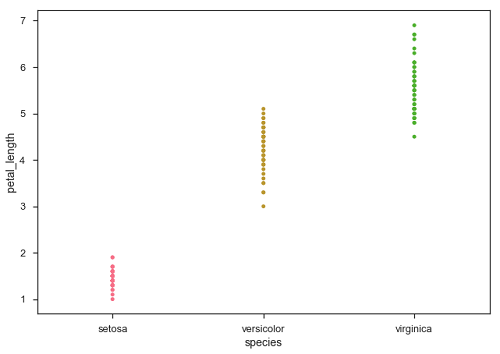
现在,可以很容易地看到点的分布。
Swarmplot()
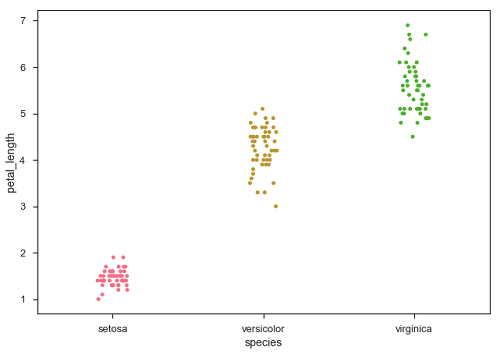
另一个可以替代"Jitter"的选项是函数swarmplot()。 此函数将散点图的每个点定位在分类轴上,从而避免重叠点 −
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()
输出