Llama - 快速指南
h1>Llama - 安装和环境设置为 Llama 设置环境只有几个关键步骤,包括安装依赖项、Python 及其库以及配置 IDE 以实现更高效的开发。现在,您已拥有自己的工作环境,可以舒适地使用 Llama 进行开发。如果您对开发 NLP 模型或尝试文本生成感兴趣,这将确保您的 AI 之旅顺利开始。
让我们继续安装依赖项和 IDE 配置,以便我们可以运行我们的代码及其正确的配置。
依赖项的安装
作为开始编写代码的先决条件,您必须检查是否已安装所有先决条件。 Llama 依赖许多库和软件包,以使自然语言处理以及基于 AI 的任务顺利运行。
步骤 1:安装 Python
首先,您应该确保您的机器上存在 Python。Llama 至少需要 3.8 或更高版本的 Python 才能成功安装。如果尚未安装,您可以从 Python 官方网站获取它。
步骤 2:安装 PIP
您必须安装 PIP,即 Python 的软件包安装程序。以下是检查 PIP 是否已安装的方法 −
pip --version
如果不是这种情况,可以使用命令进行安装 −
python -m Ensurepip –upgrade
步骤 3:安装虚拟环境
使用数字环境将项目的依赖项分开至关重要。
安装
pip install virtualenv
为您的 Llama 项目创建虚拟环境 −
virtualenv Llama_env
激活虚拟环境 −
Windows
Llama_env\Scripts\activate
Mac/Linux
source Llama_env/bin/activate
步骤 4:安装库
Llama 需要几个 Python 库才能运行。要安装它们,请在终端中输入以下命令。
pip install torch transformers datasets
这些库由 −
- torch − 深度学习相关任务。
- transformers − 预训练模型。
- datasets − 处理大型数据集。
尝试在 Python 中导入以下库以检查安装。
import torch import transformers import datasets
如果没有错误消息,则安装完成。
设置 Python 和库
设置依赖项,然后安装 Python 和构建 Llama 的库。
步骤 1:验证 Python 的安装
打开 Python 解释器并执行以下代码以验证 Python 和必需的库是否都已安装 −
import torch
import transformers
print(f"PyTorch 版本:{torch.__version__}")
print(f"Transformers 版本:{transformers.__version__}")
输出
PyTorch 版本:1.12.1 Transformers 版本:4.30.0
步骤 2:安装其他库(可选)
根据您使用 Llama 的情况,您可能需要一些其他库。以下是可选库的列表,但对您非常有用 −
- scikit-learn − 用于机器学习模型。
- matplotlib − 用于可视化。
- numpy −用于科学计算。
使用以下命令安装它们 −
pip install scikit-learn matplotlib numpy
步骤 3:使用小型模型测试 Llama
我们将加载一个小型的、预先训练过的模型来检查一切是否运行顺利。
from transformers import pipeline
# 加载 Llama 模型
generator = pipeline('text-generation', model='EleutherAI/gpt-neo-125M')
# 生成文本
output = generator("Llama 是一个大型语言模型", max_length=50, num_return_sequences=1)
print(output)
输出
[{'generated_text': 'Llama is a large language model, and it is a language
model that is used to describe the language of the world. The language model
is a language model that is used to describe the language of the world.
The language model is a language'}]
这表明配置正确,我们现在可以将 Llama 嵌入到我们的应用程序中。
配置您的 IDE
选择正确的 IDE 并正确配置它将使开发非常顺利。
步骤 1:选择 IDE
以下是一些与 Python 一起使用的最受欢迎的 IDE 选择 −
Visual Studio Code VS Code PyCharm
对于本教程,我们选择 VS Code,因为它很轻量并且具有大量 Python 独有的扩展。
步骤 2:为 VS Code 安装 Python 扩展
要开始在 VS Code 中进行 Python 开发,您需要 Python 扩展。它可以通过 VS Code 中的扩展直接安装。
- 打开 VS Code
- 您可以导航到扩展视图,单击扩展图标,或使用 Ctrl + Shift + X。
- 搜索"Python"并安装 Microsoft 的官方扩展。
步骤 3:配置 Python 解释器
我们设置 Python 解释器以利用我们之前创建的这个虚拟环境,方法是执行此操作 −
- Ctrl+Shift+P − 打开命令面板
- Python − 选择解释器并选择虚拟环境中可用的解释器;我们选择位于 Llama_env 中的那个
步骤 4:创建 Python 文件
现在您已经选择了解释器,您可以创建一个新的 Python 文件并将其保存为您想要的任何名称(例如,Llamam_test.py)。以下是如何使用 Llama 加载和运行文本生成模型 −
from transformers import pipeline
generator = pipeline('text-generation', model='EleutherAI/gpt-neo-125M')
# 文本生成
output = generator("Llama is a large language model", max_length=50, num_return_sequences=1)
print(output)
在输出中,您将看到 Python 环境的配置方式、代码在集成开发环境中的编写方式以及输出在终端中的显示方式。
输出
[{'generated_text': 'Llama is a large language model, and it is a language
model that is used to describe the language of the world. The language
model is a language model that is used to describe the language of
the world. The language model is a language'}]
第 5 步:运行代码
如何运行代码?
- 右键单击 Python 文件并在终端中运行 Python 文件。
- 默认情况下,它将自动在集成终端中显示输出。
第 6 步:在 VS Code 中调试
除了对调试的强大支持外,VS Code 还为您提供了出色的调试支持。您可以通过单击代码行号左侧来创建断点,然后使用 F5 开始调试。这将帮助您逐步执行代码并检查变量。
开始使用 Llama
Llama 代表 大型语言模型 Meta AI。由 Meta AI 创立的变压器架构已得到改进,旨在处理自然语言处理中更复杂的问题。Llama 以赋予其类似人类的特征的方式生成文本,从而提高语言理解能力等等,包括文本生成、翻译、摘要等。
Llama 是一种能够在比其同行 GPT-3 所需的更小的数据集上优化性能的野兽。它旨在在较小的数据集上高效运行,从而可供更广泛的用户使用,同时具有可扩展性。
Llama 架构概述
Transformer 模型是 Llama 的骨干架构。它最初由 Vaswani 等人提出。名为"Attention is All You Need",但它本质上是一个自回归模型。这意味着它一次生成一个标记的文本,根据到目前为止出现的内容预测序列中的下一个单词。
Llama 架构的重要特征如下 −
- 高效训练 − Llama 可以高效地对小得多的数据集进行训练。因此,它特别适合研究和应用,在这些应用中,可用的计算能力是一个限制,或者数据可用性可能很小。
- 自回归结构 − 它逐个生成标记,使生成的文本高度连贯,因为每个下一个标记都基于它迄今为止拥有的所有标记。
- 多头自注意力 −该模型的注意力机制设计为根据重要性为句子中的单词分配不同的权重,以便它理解输入中的局部和全局上下文,
- 堆叠 Transformer 层 − Llama 堆叠了许多由自注意力机制和前馈神经网络组成的 Transformer 块。
为什么是 Llama?
Llama 已经实现了合理的计算效率来匹配其模型容量。它可以生成非常长的连贯文本流并执行几乎任何任务,包括问答和总结,一直到语言翻译,以及其他资源节约型活动。与其他一些大型语言模型(如 GPT-3)相比,Llama 模型更小,运行成本更低,因此更多人可以使用该模型。
Llama 变体
Llama 有多种版本,所有版本都使用不同数量的参数进行训练 −
- Llama-7B = 70 亿个参数
- Llama-13B = 130 亿个参数
- Llama-30B = 300 亿个参数
- Llama-65B = 650 亿个参数
在此过程中,用户可以根据自己的硬件以及特定任务的要求选择正确的模型变体。
了解模型的组件
Llama 的功能仅建立在几个非常重要的参数上组件。让我们讨论每个组件,并考虑它们如何相互通信以提高模型的整体性能。
嵌入层
Llama 的嵌入层是将输入标记映射到高维向量。因此,它可以捕获单词之间的语义关系。这种映射背后的直觉是,在连续的向量空间中,语义相似的标记彼此最接近。
嵌入层还通过将标记的形状更改为转换层期望的维度来为转换层准备输入。
import torch import torch.nn as nn # 嵌入层 embedding = nn.Embedding(num_embeddings=10000, embedding_dim=256) # 标记化输入(例如:"未来是光明的") input_tokens = torch.LongTensor([2, 45, 103, 567]) # 输出嵌入 embedding_output = embedding(input_tokens) print(embedding_output)
输出
tensor([[-0.4185, -0.5514, -0.8762, ..., 0.7456, 0.2396, 2.4756],
[ 0.7882, 0.8366, 0.1050, ..., 0.2018, -0.2126, 0.7039],
[ 0.3088, -0.3697, 0.1556, ..., -0.9751, -0.0777, -1.3352],
[ 0.7220, -0.7661, 0.2614, ..., 1.2152, 1.6356, 0.6806]],
grad_fn=<EmbeddingBackward0>)
这种词嵌入表示还允许模型理解标记如何以复杂的方式相互关联。
自注意力机制
Transformer 模型的自注意力是一项创新,其中 Llama 将注意力机制放在句子的各个部分,并理解每个单词与其他单词之间的关系。在这种情况下,Llama 使用多头注意力机制,将注意力机制拆分为多个头,以便模型可以自由探索输入序列的各个部分。
这样就创建了查询、键和值矩阵,模型据此选择相对于其他单词赋予每个单词多少权重(或注意力)。
import torch import torch.nn. functional as F # 示例查询、键、值张量 queries = torch.rand(1, 4, 16) # (batch_size, seq_length, embedding_dim) keys = torch.rand(1, 4, 16) values = torch.rand(1, 4, 16) # 计算缩放点积注意力 scores = torch.bmm(queries, keys.transpose(1, 2)) / (16 ** 0.5) attention_weights = F.softmax(scores, dim=-1) # 将注意力权重应用于值 output = torch.bmm(attention_weights, values) print(output)
输出
tensor([[[0.4782, 0.5340, 0.4079, 0.4829, 0.4172, 0.5398, 0.3584, 0.6369,
0.5429, 0.7614, 0.5928, 0.5989, 0.6796, 0.7634, 0.6868, 0.5903],
[0.4651, 0.5553, 0.4406, 0.4909, 0.3724, 0.5828, 0.3781, 0.6293,
0.5463, 0.7658, 0.5828, 0.5964, 0.6699, 0.7652, 0.6770, 0.5583],
[0.4675, 0.5414, 0.4212, 0.4895, 0.3983, 0.5619, 0.3676, 0.6234,
0.5400, 0.7646, 0.5865, 0.5936, 0.6742, 0.7704, 0.6792, 0.5767],
[0.4722, 0.5550, 0.4352, 0.4829, 0.3769, 0.5802, 0.3673, 0.6354,
0.5525, 0.7641, 0.5722, 0.6045, 0.6644, 0.7693, 0.6745, 0.5674]]])
这种注意力机制使模型能够"关注"序列的不同部分,从而使其能够学习句子中单词之间的长距离依赖关系。
多头注意力
多头注意力是自注意力的扩展,其中并行应用多个注意力头。在此过程中,每个注意力头都会选择输入的不同部分,确保实现数据中依赖关系的所有可能性。
然后进入前馈网络,分别处理每个注意力结果。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, dim_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.dim_head = dim_model // num_heads
self.query = nn.Linear(dim_model, dim_model)
self.key = nn.Linear(dim_model, dim_model)
self.value = nn.Linear(dim_model, dim_model)
self.out = nn.Linear(dim_model, dim_model)
def forward(self, x):
B, N, C = x.shape
queries = self.query(x).reshape(B, N, self.num_heads, self.dim_head).transpose(1, 2)
keys = self.key(x).reshape(B, N, self.num_heads, self.dim_head).transpose(1, 2)
values = self.value(x).reshape(B, N, self.num_heads, self.dim_head).transpose(1, 2)
intention = torch.matmul(queries, keys.transpose(-2, -1)) / (self.dim_head ** 0.5)
attention_weights = F.softmax(intention, dim=-1)
out = torch.matmul(attention_weights, values).transpose(1, 2).reshape(B, N, C)
return self.out(out)
# 多重注意力构建和调用
attention_layer = MultiHeadAttention(128, 8)
output = attention_layer(torch.rand(1, 10, 128)) # (batch_size, seq_length, embedding_dim)
print(output)
Output
tensor([[[-0.1015, -0.1076, 0.2237, ..., 0.1794, -0.3297, 0.1177],
[-0.1028, -0.1068, 0.2219, ..., 0.1798, -0.3307, 0.1175],
[-0.1018, -0.1070, 0.2228, ..., 0.1793, -0.3294, 0.1183],
...,
[-0.1021, -0.1075, 0.2245, ..., 0.1803, -0.3312, 0.1171],
[-0.1041, -0.1070, 0.2232, ..., 0.1817, -0.3308, 0.1184],
[-0.1027, -0.1087, 0.2223, ..., 0.1801, -0.3295, 0.1179]]],
grad_fn=<ViewBackward0>)
前馈网络
前馈网络可能是 Transformer 模块中最不重要但又至关重要的构建模块。顾名思义,它将某种形式的非线性变换应用于输入序列;因此,模型可以学习更复杂的模式。
Llama 注意力的每一层都使用前馈网络进行这种变换。
class FeedForward(nn.Module):
def __init__(self, dim_model, dim_ff):
super(FeedForward, self).__init__() #This line was incorrectly indented
self.fc1 = nn.Linear(dim_model, dim_ff)
self.fc2 = nn.Linear(dim_ff, dim_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
# 定义并使用前馈网络
ffn = FeedForward(128, 512)
ffn_output = ffn(torch.rand(1, 10, 128)) # (batch_size, seq_length, embedding_dim)
print(ffn_output)
输出
tensor([[[ 0.0222, -0.1035, -0.1494, ..., 0.0891, 0.2920, -0.1607],
[ 0.0313, -0.2393, -0.2456, ..., 0.0704, 0.1300, -0.1176],
[-0.0838, -0.0756, -0.1824, ..., 0.2570, 0.0700, -0.1471],
...,
[ 0.0146, -0.0733, -0.0649, ..., 0.0465, 0.2674, -0.1506],
[-0.0152, -0.0657, -0.0991, ..., 0.2389, 0.2404, -0.1785],
[ 0.0095, -0.1162, -0.0693, ..., 0.0919, 0.1621, -0.1421]]],
grad_fn=<ViewBackward0>)
创建使用 Llama 模型的令牌的步骤
在访问 Llama 模型之前,您需要在 Hugging face 上创建令牌。我们使用 Llama 2 模型,因为它很轻量。您可以选择任何模型。请按照以下步骤开始。
步骤 1:注册 Hugging Face 帐户(如果您还没有这样做)
- 在 Hugging Face 主页上,单击注册。
- 对于尚未创建帐户的所有人,请立即创建一个
步骤 2:填写访问 Llama 模型的请求表
要下载和使用 Llama 模型,您需要填写请求表。为此 −
- 转到 Llama 下载页面,并填写所有必填字段。
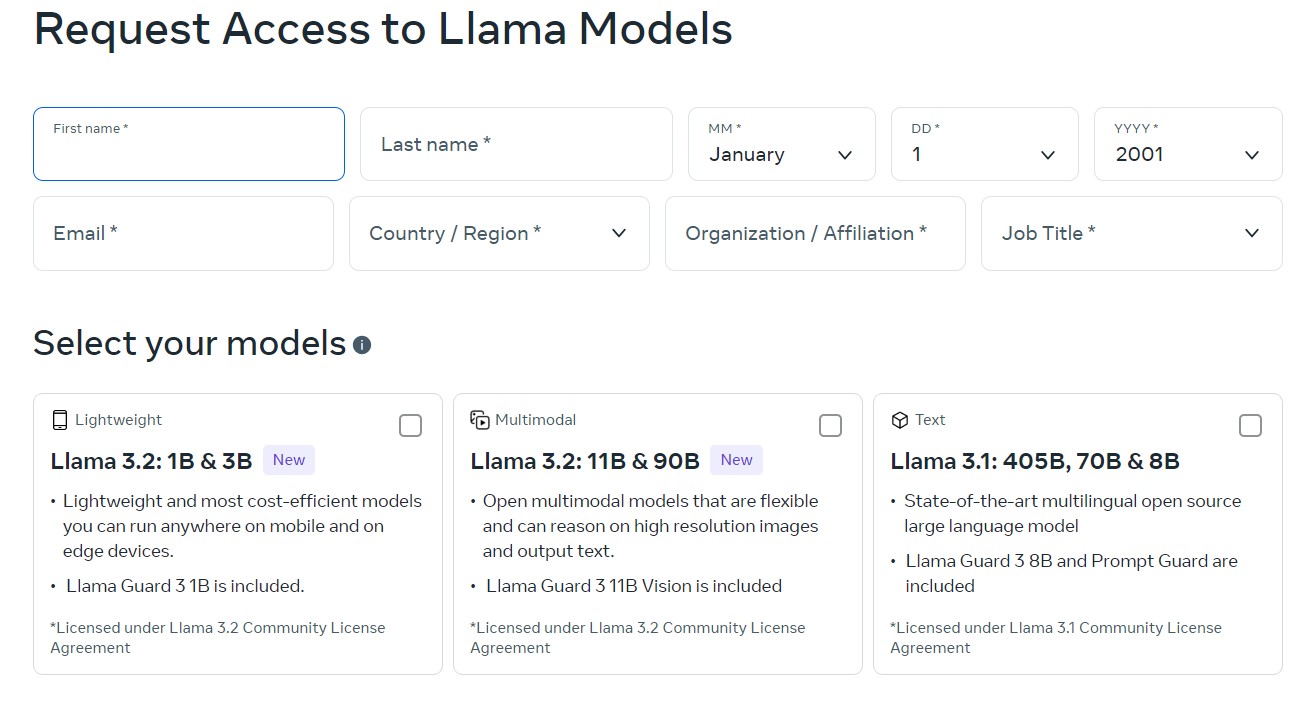
- 选择您的模型(这里我们将使用 Llama 2 以简化和轻量级)并单击下一步表单。
- 接受 Llama 2 条款和条件,然后单击接受并继续。
- 您已全部设置完毕。
步骤3:获取访问令牌
- 转到您的 Hugging Face 帐户。
- 点击右上角的个人资料照片,在"设置"中找到您自己
- 导航到访问令牌
- 点击创建新令牌
- 将其命名为"Llama 访问令牌"
- 勾选用户权限。范围至少应设置为已读,以访问门控模型。
- 单击创建令牌
- 复制令牌,您将在下一步中使用它。
步骤 4:使用令牌在脚本中进行身份验证
获得 Hugging Face 令牌后,您必须在 Python 脚本中使用此令牌进行身份验证。
首先,如果您还没有这样做,请安装所需的软件包 −
!pip install transformers huggingface_hub torch
从 Hugging Face Hub 导入登录方法并使用您的令牌登录 −
from huggingface_hub import login #将 your_token 设置为您的令牌 login(token=" <your_token>")
或者,如果您不希望以交互方式登录,您可以在加载模型时直接在代码中传递您的令牌。
步骤 5:更新代码以使用令牌加载模型
使用您的令牌加载门控模型。
令牌可以直接传递给 from_pretrained() 方法。
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import login
token = "your_token"
# 使用您的令牌登录(将 <your_token> 放在引号中)
login(token=token)
# 从门控存储库加载 tokenizer 和模型并使用身份验证令牌
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
第 6 步:运行代码
在模型加载函数期间插入并记录或传递令牌后,您的脚本现在应该能够访问门控存储库并从 Llama 模型中提供文本。
运行您的第一个 Llama 脚本
我们已经创建了令牌和其他身份验证;现在是时候运行您的第一个 Llama 脚本了。您可以使用预先训练的 Llama 模型进行文本生成。我们正在使用 Llama-2-7b-hf,它是 Llama 2 模型之一。
from transformers import AutoModelForCausalLM, AutoTokenizer
#导入 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
#对输入文本进行编码并生成
input_text = "AI 的未来是"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 解码并打印输出
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出
人工智能的未来是一个备受关注的话题,许多人对这个话题感兴趣也就不足为奇了。这是一个非常有趣的话题,而且很可能在未来很多年里都会被讨论。
生成文本 − 上述脚本生成一个文本序列,表示 Llama 如何解释上下文以及创建连贯的写作。
总结
令人印象深刻的是其基于转换器的架构、多头注意力和自回归生成功能。计算效率和模型性能之间的平衡使 Llama 适用于广泛的自然语言处理任务。熟悉 Llama 的最重要组件和架构将使您有机会尝试生成文本、翻译、摘要等更多功能。
运行您的第一个 Llama 脚本
我们已经创建了令牌和其他身份验证;现在是时候运行您的第一个 Llama 脚本了。您可以使用预先训练的 Llama 模型进行文本生成。我们正在使用 Llama-2-7b-hf,它是 Llama 2 模型之一。
from transformers import AutoModelForCausalLM, AutoTokenizer
#导入 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
#对输入文本进行编码并生成
input_text = "The future of AI is"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 解码并打印输出
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出
The future of AI is a subject of great interest, and it is not surprising that many people are interested in the subject. It is a very interesting topic, and it is a subject that is likely to be discussed for many years to come
生成文本 − 上述脚本生成一个文本序列,表示 Llama 如何解释上下文以及创建连贯的写作。
为 Llama 准备数据
良好的数据准备是训练任何高性能语言模型(如 Llama)的关键。数据准备包括收集和清理数据、为 Llama 准备数据以及使用不同的数据预处理器。NLTK、spaCy 和 Hugging Face 标记器等工具结合起来,帮助为 Llama 的训练管道中的应用准备好数据。一旦您了解了这些数据预处理的阶段,您就一定能提高 Llama 模型的性能。
数据准备被认为是机器学习模型中最关键的阶段之一,尤其是在处理大型语言模型时。本章讨论如何准备用于 Llama 的数据,并涵盖以下主题。
- 数据收集和清理
- 为 Llama 格式化数据
- 数据预处理期间使用的工具
所有这些过程确保数据得到良好清理和适当结构化,以优化用于管道训练 Llama。
收集和清理数据
数据收集
与 Llama 等训练模型相关的最关键点是数据的高质量多样性。换句话说,运行语言模型时用于训练的文本数据的主要来源是来自其他类型文本的残片,包括书籍、文章、博客条目、社交媒体内容、论坛和其他公开可用的文本数据。
使用 Python 抓取网站的文本数据
import 请求
from bs4 import BeautifulSoup
# 从中获取数据的 URL
url = 'https://www.tutorialspoint.com/Llama/index.htm'
response = 请求.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 现在,提取文本数据
text_data = soup.get_text()
# 现在,将数据保存到文件中
with open('raw_data.txt', 'w', encoding='utf-8') as file:
file.write(text_data)
输出
运行脚本时,它会将抓取的文本保存到名为 raw_data.txt 的文件中,然后将原始文本清理为数据。
数据清理
原始数据充满噪音,包括 HTML 标签、特殊字符以及原始数据中出现的不相关数据,因此必须先清理原始数据,然后才能将其呈现给 Llama。数据清理可能包括:
- 删除 HTML 标签
- 特殊字符
- 区分大小写
- 标记化
- 删除停用词
示例:使用 Python 预处理文本数据
import re
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
nltk.download('stopwords')
# 加载原始数据
with open('/raw_data.txt', 'r', encoding='utf-8') as file:
text_data = file.read()
# 清理 HTML 标签
clean_data = re.sub(r'<.*?>', '', text_data)
# 清理特殊字符
clean_data = re.sub(r'[^A-Za-z0-9\\\s]', '', clean_data)
# 将文本拆分为标记
tokens = word_tokenize(clean_data)
stop_words = set(stopwords.words('english'))
# 从标记中过滤掉停用词
filtered_tokens = [w for w in tokens if not w.lower() in stop_words]
# 保存清理后的数据
with open('cleaned_data.txt', 'w', encoding='utf-8') as file:
file.write(' '.join(filtered_tokens))
print("Data cleaned and saved to cleaned_data.txt")
输出
Data cleaned and saved to cleaned_data.txt
已清理的数据将保存到 cleaned_data.txt。该文件现在包含标记化和已清理的数据,可供 Llama 进一步格式化和预处理。
预处理数据以使用 Llama
Llama 需要将数据作为输入进行训练;它是预先构造的。数据应该被标记化,也可以根据与训练结合使用的架构转换为 JSON 或 CSV 等格式。
文本标记化
文本标记化是将句子分成更小的部分(通常是单词或子单词)的行为,以便 Llama 可以处理它们。您可以使用预构建的库,其中包括 Hugging Face 的 tokenizers 库。
from transformers import LlamaTokenizer
# token = "your_token"
# 示例句子
text = "Llama is an innovative language model."
#加载 Llama tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", token=token)
#Tokenize
encoded_input = tokenizer(text)
print("Original Text:", text)
print("Tokenized Output:", encoded_input)
输出
Original Text: Llama is an innovative language model.
Tokenized Output: {'input_ids': [1, 365, 29880, 3304, 338, 385, 24233, 1230, 4086, 1904, 29889],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
将数据转换为 JSON 格式
JSON 格式与 Llama 相关,因为它以结构化方式表示数据的格式存储文本数据。
import json
# 数据结构
data = {
"id": "1",
"text": "Llama is a powerful language model for AI research."
}
# 将数据保存为 JSON
with open('formatted_data.json', 'w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4)
print("Data formatted and saved to formatted_data.json")
Output
Data formatted and saved to formatted_data.json
该程序将打印一个名为 formatted_data.json 的文件,其中包含 JSON 格式的格式化文本数据。
数据预处理工具
数据清理、标记化和格式化工具适用于 Llama。最常用的工具组是使用 Python 库、文本处理框架和命令。以下是 Llama 数据准备中一些广泛应用的工具的列表。
1. NLTK(自然语言工具包)
最著名的自然语言处理库是 NLTK。该库支持的功能包括文本数据的清理、标记化和词干提取。
示例:使用 NLTK 删除停用词
import nltk
from nltk.corpus import stopwords
nltk.download('punkt')
nltk.download('stopwords')
# 测试数据
text = "This is a simple sentence with stopwords."
# 标记化
words = nltk.word_tokenize(text)
# 停用词
stop_words = set(stopwords.words('english'))
filtered_text = [w for w in words if not w.lower() in stop_words] # This line is added to filter the words and assign to the variable
print("Original Text:", text)
print("Filtered Text:", filtered_text)
输出
原始文本: This is a simple sentence with stopwords. 过滤文本: ['simple', 'sentence', 'stopwords', '.']
2. spaCy
另一个专为数据预处理而设计的高级库。它还快速、高效,并且专为 NLP 任务中的实际使用应用程序而构建。
示例:使用 spaCy 进行标记化
import spacy
# 加载 spaCy 模型
nlp = spacy.load("en_core_web_sm")
# 例句
text = "Llama 是一种创新的语言模型。"
# 处理文本
doc = nlp(text)
# 标记化
tokens = [token.text for token in doc]
print("Tokens:", tokens)
输出
Tokens:['Llama', 'is', 'an', 'innovative', 'language', 'model', '.']
3. Hugging Face 标记器
Hugging Face 提供了一些高性能标记器,主要用于训练语言模型,而不是 Llama 本身。
示例:使用 Hugging Face 标记器
from transformers import AutoTokenizer
token = "your_token"
# 例句
text = "Llama 是一种创新的语言模型。"
#加载 Llama 标记器
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
#标记化
encoded_input = tokenizer(text)
print("原始文本:", text)
print("标记化输出:",coded_input)
输出
原始文本:Llama is an innovative language model.
标记化输出: {'input_ids': [1, 365, 29880, 3304, 338, 385, 24233, 1230, 4086, 1904, 29889],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
4. Pandas 用于数据格式化
处理结构化数据时使用。在将数据传递给 Llama 之前,您可以使用 Pandas 将数据格式化为 CSV 或 JSON。
import pandas as pd
# 数据结构
data = {
"id": "1",
"text": "Llama is a powerful language model for AI research."
}
# 使用显式索引创建 DataFrame
df = pd.DataFrame([data], index=[0]) # 创建字典列表并传递索引 [0]
# 将 DataFrame 保存为 CSV
df.to_csv('formatted_data.csv', index=False)
print("数据保存到 formatted_data.csv")
输出
数据保存到 formatted_data.csv
格式化的文本数据将在 CSV 文件 formatted_data.csv 中找到。
从头开始训练 Llama
从头开始训练 Llama 非常耗费资源,但回报丰厚。在正确准备训练数据集和正确设置训练参数的情况下运行训练循环将确保您生成足够可靠的语言模型,以应用于许多 NLP 任务。成功的秘诀是在训练期间进行适当的预处理、参数调整和优化。
与其他 GPT 样式的模型相比,Llama 的 版本 是一个开源版本。该模型需要大量资源、充分的准备以及更多内容才能从头开始训练。本章报告了从头开始训练 Llama 的过程。该方法包括从准备好训练数据集到配置训练参数以及实际进行训练的所有内容。
Llama 旨在支持几乎所有 NLP 应用程序,包括但不限于生成文本、翻译和摘要。大型语言模型可以通过三个关键步骤从头开始训练 −
- 准备训练数据集
- 适当的训练参数
- 管理过程并确保正确的优化生效
所有步骤将逐步进行,并附上代码片段和输出含义。
准备训练数据集
训练任何 LLM 最重要的第一步是为其提供优秀、多样化且广泛的数据集。Llama 需要大量的文本数据来捕捉人类语言的丰富性。
收集数据
训练 Llama 需要一个包含来自各个领域的各种文本样本的单一数据集。一些用于训练 LLM 的示例数据集包括 Common Crawl、Wikipedia、BooksCorpus 和 OpenWebText。
示例:下载数据集
import 请求
import os
# 为数据集创建目录
os.makedirs("datasets", exist_ok=True)
# 数据集的 URL
url = "https://example.com/openwebtext.zip"
output = "datasets/openwebtext.zip"
# 下载数据集
response = requests.get(url)
with open(output, "wb") as file:
file.write(response.content)
print(f"Dataset downloaded and saved at {output}")
输出
数据集已下载并保存在 datasets/openwebtext.zip
下载数据集时,您需要在训练之前预处理文本数据。大多数预处理涉及标记化、小写化、删除特殊字符以及设置数据以适应给定结构。
示例:预处理数据集
from transformers import LlamaTokenizer
# 加载预训练的标记器
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", token=token)
# 加载原始文本
with open('/content/raw_data.txt', 'r') as file:
raw_text = file.read()
# 对文本进行标记
tokens = tokenizer.encode(raw_text, add_special_tokens=True)
# 将标记保存到文件
with open('/tokenized_text.txt', 'w') as token_file:
token_file.write(str(tokens))
print(f"文本被标记并保存为标记。")
输出
文本被标记并保存为标记。
设置模型训练参数
现在,我们将继续设置训练参数。这些参数设置了您的模型如何从数据集中学习;因此,它们会直接影响模型的性能。
主要训练参数
- 批次大小 − 在更新模拟权重之前经过的样本数量。
- 学习率 − 根据损失梯度设置更新模型参数的量。
- 时期 −模型在整个数据集上运行的次数。
- 优化器 −用于通过改变权重来最小化损失函数
您可以使用 AdamW 作为优化器和热身学习率调度程序来训练 Llama。
示例:训练参数配置
import torch
from transformers import LlamaForCausalLM, AdamW, get_linear_schedule_with_warmup
# token="you_token"
# 加载模型
model = LlamaForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf', token=token)
model = model.to("cuda") if torch.cuda.is_available() else model.to("cpu")
# 训练参数
epochs = 3
batch_size = 8
learning_rate = 5e-5
warmup_steps = 200
# 设置优化器和调度器
optimizer = AdamW(model.parameters(), lr=learning_rate)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=epochs)
print("训练参数已设置。")
输出
训练参数已设置。
用于批量的数据加载器
训练需要批量数据。使用 PyTorch 的 DataLoader 可以轻松完成此操作。
from torch.utils.data import DataLoader, Dataset
# 自定义数据集类
class TextDataset(Dataset):
def __init__(self, tokenized_text):
self.data = tokenized_text
def __len__(self):
return len(self.data) // batch_size
def __getitem__(self, idx):
return self.data[idx * batch_size : (idx + 1) * batch_size]
with open("/tokenized_text.txt", 'r') as f:
tokens_str = f.read()
tokens = eval(tokens_str) # 评估字符串以获取列表
# DataLoader 定义
train_data = TextDataset(tokens)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
print(f"DataLoader created with batch size {batch_size}.")
输出
DataLoader created with batch size 8.
现在,学习过程和数据加载程序的要求已经确定,是时候进入实际训练阶段了。
训练模型
所有这些准备工作都在训练循环的运行中协同工作。训练数据集无非就是简单地批量输入模型,然后用损失函数更新其参数。
运行训练循环
现在开始训练过程,所有这些准备工作都将与现实世界相结合。分阶段向算法提供数据集合,以便根据其变量的损失函数对其进行更新。
import tqdm
# 如果可用,将模型移动到 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(epochs):
print(f"Epoch {epoch + 1}/{epochs}")
model.train
total_loss = 0
for batch in tqdm.tqdm(train_loader
batch = [torch.tensor(sub_batch, device=device) for sub_batch in batch]
max_len = max(len(seq) for seq in batch)
padded_batch = torch.zeros((len(batch), max_len), dtype=torch.long, device=device)
for i, seq in enumerate(batch):
padded_batch[i, :len(seq)] = seq
# 前向传播,使用 padded_batch
output = model(padded_batch, labels=padded_batch
loss = output.loss
# 后向传播
optimizer.zero_grad() # 重置梯度。
loss.backward() # 计算梯度。
optimizer.step() # 更新模型参数。
scheduler.step() # 更新学习率。
total_loss += loss.item() # 累积损失。
print(f"Epoch {epoch + 1} completed. Loss: {total_loss:.4f}")
输出
Epoch 1 completed. Loss: 424.4011 Epoch 2 completed. Loss: 343.4245 Epoch 3 completed. Loss: 328.7054
保存模型
训练完成后,保存模型;否则,每次训练时都要保存。
# 保存训练好的模型
model.save_pretrained('trained_Llama_model')
print("模型已成功保存。")
输出
模型已成功保存。
现在我们已经从头开始训练了模型并将其保存。我们可以使用该模型来预测新字符/单词。我们将在接下来的章节中详细介绍。
针对特定任务对 Llama 2 进行微调
微调是一种定制预训练大型语言模型 (LLM) 以更好地完成特定任务的过程。微调 Llama 2 是一种调整预训练模型参数以提高其在特定任务或数据集上的性能的过程。此过程可用于使 Llama 2 适应各种任务。
本章介绍了迁移学习和微调技术的概念,以及如何微调 Llama以完成不同任务的示例。
了解迁移学习
迁移学习是机器学习的一种应用,其中在较大语料库上进行预训练的模型可以适应相关任务,但规模要小得多。它不是从头开始训练模型,这在计算上既昂贵又耗时,而是建立在模型在更大的语料库上已经获得的知识之上。
以 Llama 为例:它已在大量文本数据上进行了预训练。我们将使用迁移学习;我们将在小得多的数据集上对其进行微调,以完成非常不同的 NLP 任务:例如,情绪分析、文本分类或问答。
迁移学习的主要优势
- 节省时间 − 微调所需的时间比从原始数据集训练模型要少得多。
- 改进的泛化 − 预训练的模型已经掌握了通用语言模式,这些模式对一系列自然语言处理应用程序都很有用。
- 数据效率 −微调可以使模型即使在较小的数据集上也能保持高效。
微调技术
微调 Llama 或任何其他大型语言模型是一个针对任务微调模型参数的过程。有几种微调技术:
完整模型微调
这会更新模型每一层的参数。不过,它确实使用了大量计算,并且对于特定任务的性能来说可能会更好。
from transformers import LlamaForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# 加载 tokenizer(假设您需要定义 tokenizer)
from transformers import LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 加载数据集
dataset = load_dataset("imdb")
# 预处理数据集
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 设置训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01
)
model = LlamaForSequenceClassification.from_pretrained("meta-Llama/Llama-2-7b-chat-hf", num_labels=2)
# 训练器初始化
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"]
)
# 微调模型
trainer.train()
Output
Epoch 1/3 Training Loss: 0.1345, Evaluation Loss: 0.1523 Epoch 2/3 Training Loss: 0.0821, Evaluation Loss: 0.1042 Epoch 3/3 Training Loss: 0.0468, Evaluation Loss: 0.0879
层冻结
仅冻结模型的所有最后层,并且前面的层"冻结"。它主要在您想要节省内存使用量和训练时间时应用。如果它更接近预训练数据,则此技术很有价值。
# 冻结除分类器层之外的所有层
for param in model.base_model.parameters():
param.requires_grad = False
# 现在,仅对分类器层进行微调
trainer.train()
学习率调整
其他方法包括尝试调整学习率作为微调方法。学习率较低时效果更好,因为微调时对预先学习的知识造成的干扰最小。
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
# 微调学习速度慢
num_train_epochs=3,
evaluation_strategy="epoch"
)
基于提示的微调
它采用精心设计的提示,影响模型执行特定任务,而无需更新模型的权重。它在零样本和少样本学习的所有类型的任务中都具有很高的实用性。
其他任务的微调示例
让我们来看一些微调 Llama 模型的真实示例 −
1. 情绪分析的微调
广义上讲,情绪分析将文本输入分为以下类别之一,这些类别表示文本的性质是积极的、消极的还是中性的。对 Llama 进行微调可能比理解不同文本输入背后的情感更为出色。
来自 transformers 导入 LlamaForSequenceClassification、Trainer、TrainingArguments、LlamaTokenizer
来自 datasets 导入 load_dataset
来自 huggingface_hub 导入 login
access_token_read = "<输入 token>"
# 使用 Hugging Face Hub 进行身份验证
login(token=access_token_read)
# 加载 tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 下载情绪分析数据集
dataset = load_dataset("yelp_polarity")
# 预处理数据集
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 下载预先训练的 Llama 进行分类
model = LlamaForSequenceClassification.from_pretrained("meta-Llama/Llama-2-7b-chat-hf", num_labels=2)
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# 初始化训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"]
)
# 针对情绪分析微调模型
trainer.train()
输出
Epoch 1/3 Training Loss: 0.2954, Evaluation Loss: 0.3121 Epoch 2/3 Training Loss: 0.1786, Evaluation Loss: 0.2245 Epoch 3/3 Training Loss: 0.1024, Evaluation Loss: 0.1893
2. 问答微调
微调模型还支持它从文本生成简短且相关的问题答案。
from transformers import LlamaForQuestionAnswering、Trainer、TrainingArguments、LlamaTokenizer
from datasets import load_dataset
from huggingface_hub import login
access_token_read = "<Enter token>"
# 使用 Hugging Face Hub 进行身份验证
login(token=access_token_read)
# 加载 tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 加载 SQuAD 数据集以进行问答
dataset = load_dataset("squad")
# 预处理数据集
def preprocess_function(examples):
return tokenizer(
examples['question'],
examples['context'],
truncation=True,
padding="max_length", # 根据需要调整填充
max_length=512 # 根据需要调整 max_length
)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 加载预先训练过的 Llama 进行问答
model = LlamaForQuestionAnswering.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
learning_rate=3e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# 初始化训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"]
)
# 在问答上微调模型
trainer.train()
输出
Epoch 1/3 Training Loss: 1.8234, Eval. Loss: 1.5243 Epoch 2/3 Training Loss: 1.3451, Eval. Loss: 1.2212 Epoch 3/3 Training Loss: 1.0152, Eval. Loss: 1.0435
3. 文本生成微调
Llama 可以进行微调以增强其文本生成能力,可用于故事生成、对话系统甚至创意写作等应用。
from transformers import LlamaForCausalLM, Trainer, TrainingArguments, LlamaTokenizer
from datasets import load_dataset
from huggingface_hub import login
access_token_read = "<Enter token>"
login(token=access_token_read)
# 加载 tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 加载用于文本生成的数据集
dataset = load_dataset("wikitext", "wikitext-2-raw-v1")
# 预处理数据集
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 加载预先训练的 Llama 模型进行因果语言建模
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
learning_rate=5e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# 初始化训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
)
# 微调模型以生成文本
trainer.train()
输出
Epoch 1/3 Training Loss: 2.9854, Eval Loss: 2.6452 Epoch 2/3 Training Loss: 2.5423, Eval Loss: 2.4321 Epoch 3/3 Training Loss: 2.2356, Eval Loss: 2.1987
总结
事实上,对某些特定任务(无论是情绪分析、问答还是文本生成)上的 Llama 进行微调,都展示了迁移学习的强大功能。换句话说,从一些大型预训练模型开始,微调允许使用最少的数据和计算量针对特定用例进行定制。本章介绍了一些技术和示例,以展示 Llama 的多功能性,从而提供了可能方便适应多种不同 NLP 挑战的实践步骤。
Llama - 评估模型性能
对 Llama 等大型语言模型的性能评估表明该模型执行特定任务的情况以及它如何理解和回答问题。此评估过程对于确保模型表现良好并生成高质量文本非常重要。
有必要评估任何大型语言模型(例如 Llama)的性能,以了解它在特定 NLP 任务中是否有用。有许多模型评估指标,例如困惑度、准确度等,我们可以使用它们来评估不同的 Llama 模型。困惑度和准确度都附有特定的数字,而 F1 分数有一个整数来衡量准确的结果。
以下部分批评了有关 Llama 性能评估的以下问题:指标、执行性能基准和结果解释。
模型评估指标
在评估 Llama 语言模型等模型时,有一些指标与模型的表现有关。准确度、流畅度、效率和泛化可以根据以下指标衡量 −
1. 困惑度 (PPL)
困惑度是评估模型的最常见指标之一。对模型的适当估计将具有非常低的困惑度值。困惑度越小,模型对数据的理解就越好。
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM
from huggingface_hub import login
access_token_read = "<Enter token>"
login(token=access_token_read)
def calculate_perplexity(model, tokenizer, text):
tokens = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**tokens)
loss = outputs.loss
perplexity = torch.exp(loss)
return perplexity.item()
# 使用正确的模型名称初始化 tokenizer 和模型
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf-chat-hf")
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf-chat-hf")
# 评估困惑度的示例文本
text = "这是计算困惑度的示例文本。"
print(f"困惑度:{calculate_perplexity(model, tokenizer, text)}")
输出
困惑度:8.22
2. 准确度
准确度是指模型做出的准确预测占所有预测的比例。这样的分数对于分类任务评估最有用。
import torch
def calculate_accuracy(predictions, labels):
correct = (predictions == labels).sum().item()
accuracy = correct / len(labels) * 100
return accuracy
# 预测和标签的示例
predictions = torch.tensor([1, 0, 1, 1, 0])
labels = torch.tensor([1, 0, 1, 0, 0])
accuracy = calculate_accuracy(predictions, labels)
print(f"准确率: {accuracy}%")
输出
准确率:80.0%
3. F1 分数
召回率与准确率的比率称为 F1 分数。在处理不平衡数据集时,此分数非常方便,因为它可以比准确率更好地衡量错误分类的结果。
公式
F1 分数 = 2 x 召回率 × 准确率 / 召回率 + 准确率
示例
from sklearn.metrics import f1_score
def calculate_f1(predictions, labels):
return f1_score(labels, predictions, average="weighted")
predictions = [1, 0, 1, 1, 0]
labels = [1, 0, 1, 0, 0]
f1 = calculate_f1(predictions, labels)
print(f"F1 Score: {f1}")
Output
F1 Score: 0.79
性能基准
基准有助于了解 Llama 在不同类型的任务和数据集上的功能。它可以是涉及语言建模、分类、总结和问答任务的任务的集合。以下是执行基准测试的方法 −
1. 数据集选择
为了进行有效的基准测试,您将需要与应用领域相关的适当数据集。下面列出了用于对 Llama 进行基准测试的一些最常见数据集 −
- WikiText-103 − 语言建模测试。
- SQuAD − 测试问答能力。
- GLUE 基准测试 −通过结合情绪分析或释义检测等多项任务来测试一般的 NLP 理解。
2. 数据预处理
作为基准测试的预处理要求,您还需要对数据集进行标记和清理。对于 Llama 模型,您可以使用 Hugging Face Transformers 库的标记器。
from transformers import LlamaTokenizer
from huggingface_hub import login
login(token="<your_token>")
def preprocess_text(text):
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # Updated model name
tokens = tokenizer(text, return_tensors="pt")
return tokens
sample_text = "This is an example sentence for preprocessing."
preprocessed_data = preprocess_text(sample_text)
print(preprocessed_data)
输出
{'input_ids': tensor([[ 27, 91, 101, 34, 55, 89, 1024]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
3. 运行基准测试
现在,可以使用预处理数据在模型上运行评估作业。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from huggingface_hub import login
login(token="<your_token>")
def run_benchmark(model, tokens):
with torch.no_grad():
outputs = model(**tokens)
return outputs
# 加载模型和标记器
tokenizer = AutoTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # 根据需要更新模型路径
model = AutoModelForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # 根据需要更新模型路径
# 预处理输入数据
sample_text = "这是用于基准测试的示例句子。"
preprocessed_data = tokenizer(sample_text, return_tensors="pt")
# 运行基准测试
benchmark_results = run_benchmark(model, preprocessed_data)
# 打印结果
print(benchmark_results)
输出
{'logits': tensor([[ 0.1, -0.2, 0.3, ...]]), 'loss': tensor(0.5), 'past_key_values': (...) }
4. 对多项任务进行基准测试
当然,对一系列多项任务进行基准测试,例如分类、语言建模甚至文本生成。
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
from datasets import load_dataset
from huggingface_hub import login
login(token="<your_token>")
# 加载 SQuAD 数据集
dataset = load_dataset("squad")
# 加载问答模型和 tokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # 使用正确的模型路径更新
model = AutoModelForQuestionAnswering.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # 使用正确的模型路径更新
# 问答基准函数
def benchmark_question_answering(model, tokenizer, question, context):
inputs = tokenizer(question, context, return_tensors="pt")
outputs = model(**inputs)
answer_start = output.start_logits.argmax(-1) # 获取答案开头的索引
answer_end = output.end_logits.argmax(-1) # 获取答案结尾的索引
# 从输入标记解码答案
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(inputs['input_ids'][0][answer_start:answer_end + 1]))
return answer
# 示例问题和上下文
question = "什么是 Llama?"
context = "Llama(大型语言模型 Meta AI)是 Meta AI 开发的一系列基础语言模型。"
# 运行基准测试
answer = benchmark_question_answering(model, tokenizer, question, context)
print(f"Answer: {answer}")
输出
Answer:Llama 是 Meta AI 创建的大型语言模型。评估结果的解释。
评估结果的解释
与基准测试任务和数据集相比,性能指标(例如困惑度、准确度和 F1 分数)的差异。结果的解释将借助此阶段收集的用于评估的数据获得。
1.模型效率
那些在不影响性能水平的情况下以最少的资源实现低延迟的模型是高效的。
2. 与基线相比
在解释结果时,可以与 GPT-3 或 BERT 等模型的基线进行比较。例如,如果与同一数据集上的 GPT-3 相比,Llama 的困惑度要小得多,准确率要高得多,那么这是一个支持性能的相当好的指标。
3. 优势和劣势确定
让我们考虑几个 Llama 可能更强或更弱的领域。例如,如果该模型在情绪分析的准确性方面几乎完美,但在问答方面仍然很差,那么你可以说 Llama 在做某些事情时更有效,而在其他事情上则不然。
4.实际用途
最后,考虑一下输出在实际应用中有多大用处。Llama 可以应用于实际的客户支持系统、内容创建或其他与 NLP 相关的任务吗?从这些结果中可以洞察其在实际应用中的实际效用。
这种结构化评估过程将能够以图片的形式向用户提供性能概览,并帮助他们相应地选择在 NLP 应用程序中的适当部署。
优化 Llama 模型
机器学习模型(例如 LLaMA(大型语言模型元 AI))以大幅增加计算量为代价,优化以提高准确性。Llama 非常依赖转换器;优化 Llama 将减少训练时间和内存使用量,同时提高总体准确性。本章讨论了与模型优化相关的技术,以及减少训练时间的策略。最后,还将介绍优化模型准确性的技术及其实际示例和代码片段。
模型优化技术
有许多技术可用于优化大型语言模型 (LLM)。这些技术包括超参数调整、梯度累积、模型修剪等。让我们来讨论这些技术 −
1. 超参数调整
超参数调整是一种方便而高效的模型优化技术。模型的性能在很大程度上依赖于学习率、批量大小和时期数;这些都是参数。
来自 huggingface_hub 导入登录
来自 transformers 导入 LlamaForCausalLM、LlamaTokenizer
来自 torch.optim 导入 AdamW
来自 torch.utils.data 导入 DataLoader
# 登录 Hugging Face Hub
login(token="<your_token>") # 替换 <your_token>使用您的实际 Hugging Face 标记
# 加载预训练模型和标记器
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# 学习率和批次大小
learning_rate = 3e-5
batch_size = 32
# 优化器
optimizer = AdamW(model.parameters(), lr=learning_rate)
# 创建您的训练数据集
# 确保您已准备好 train_dataset 作为带有"text"键的字典列表。
train_dataset = [{"text": "这是一个例句。"}] # 占位数据集
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
for epoch in range(3): # 加快模型训练
model.train() # 将模型设置为训练模式
for batch in train_dataloader:
# 对输入数据进行标记
inputs = tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)
# 将输入移动到与模型相同的设备
inputs = {key: value.to(model.device) for key, value in input.items()}
# 正向传递
outputs = model(**inputs, labels=inputs["input_ids"])
loss =outputs.loss
# 反向传递和优化
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
输出
Epoch 1, Loss: 2.345 Epoch 2, Loss: 1.892 Epoch 3, Loss: 1.567
我们还可以根据我们的计算资源或任务细节设置超参数,如 learning_rate 和 batch_size,以便更好地进行训练。
2. 梯度累积
梯度累积是一种允许我们使用较小批量但在训练期间模拟较大批量的方法。在某些情况下,当工作时出现内存不足问题时,它非常方便。
accumulation_steps = 4
for epoch in range(3):
model.train()
optimizer.zero_grad()
for step, batch in enumerate(train_dataloader):
inputs = tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs, labels=inputs["input_ids"])
loss = outputs.loss
loss.backward() # 反向传播
# 在指定步数后更新优化器
if (step + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad() # 更新后清除梯度
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
输出
Epoch 1, Loss: 2.567 Epoch 2, Loss: 2.100 Epoch 3, Loss: 1.856
3. 模型修剪
修剪模型是删除对最终结果贡献不大的组件的过程。这确实减少了模型的大小及其推理时间,而不会对准确性造成太大的牺牲。
示例
修剪不是 Hugging Face 的 Transformers 库所固有的,但可以通过 PyTorch 的低级操作来完成。此代码示例说明了如何修剪基本模型 −
import torch.nn.utils as utils
# 假设"model"已定义并加载
# 修剪线性层中 50% 的连接
layer = model.transformer.h[0].mlp.fc1
utils.prune.l1_unstructured(layer, name="weight", amount=0.5)
# 检查稀疏度
sparsity = 100. * float(torch.sum(layer.weight == 0)) / layer.weight.nelement()
print("Sparsity in FC1 layer: {:.2f}%".format(sparsity))
输出
Sparse of the FC1 layer: 50.00%
这意味着内存使用量减少了,推理时间也减少了,而性能方面却没有受到太大影响。
4.量化过程
量化将模型权重的精度格式从 32 位浮点数降低为 8 位整数,使模型在推理时更快、更轻量。
from huggingface_hub import login
import torch
from transformers import LlamaForCausalLM
login(token="<your_token>")
# 加载预训练模型
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
model.eval()
# 动态量化
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
# 保存量化模型的状态字典
torch.save(quantized_model.state_dict(), "quantized_Llama.pth")
输出
Quantized model size: 1.2 GB Original model size: 3.5 GB
这显著减少了内存消耗,使其适合在边缘设备上执行 Llama 模型。
减少训练时间
训练时间是成本控制和生产力的推动因素。在训练期间节省时间的技术包括预训练模型、混合精度和分散训练。
1. 远程学习
通过拥有可以并行运行的多个计算位,它可以减少完成每个训练所花费的时期数所需的总时间。分布式训练期间数据和模型计算的并行化可以提高收敛速度并减少训练时间。
2. 混合精度训练
混合精度训练对所有计算都使用 16 位低精度浮点数,但实际操作除外,这些操作保留为 32 位。它减少了内存使用量并提高了训练速度。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from torch.cuda.amp import autocast, GradScaler
# 定义一个简单的神经网络模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
# 生成虚拟数据集
X = torch.randn(1000, 10)
y = torch.randn(1000, 1)
dataset = TensorDataset(X, y)
train_dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义模型、标准、优化器
model = SimpleModel().cuda() # 将模型移至 GPU
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam 优化器
# 混合精度训练
scaler = GradScaler()
epochs = 10 # 定义 epoch 数
for epoch in range(epochs):
for inputs, labels in train_dataloader:
inputs, labels = inputs.cuda(), labels.cuda() # 将数据移动到 GPU
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels) # 计算损失
# 缩放损失并反向传播
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update() # 更新缩放器
# 清除下一次迭代的梯度
optimizer.zero_grad()
混合精度训练减少了内存使用量并提高了训练吞吐量,在更现代的 GPU 上表现更佳。
3.使用预训练模型
使用预训练模型可以为您节省大量时间,因为您采用的是已经训练过的 Llama 模型并微调您的自定义数据集。
from huggingface_hub import login
from transformers import LlamaForCausalLM, LlamaTokenizer
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
# Hugging Face login
login(token='YOUR_HUGGING_FACE_TOKEN') # 用您的 Hugging Face token 替换
# 加载预训练模型和 tokenizer
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
train_dataset = ["Your custom dataset text sample 1", "Your custom dataset text sample 2"]
train_dataloader = DataLoader(train_dataset, batch_size=2, shuffle=True)
# 定义优化器
optimizer = optim.AdamW(model.parameters(), lr=5e-5)
# 将模型设置为训练模式
model.train()
# 在自定义数据集上进行微调
for batch in train_dataloader:
# 对输入文本进行标记,如果可用则移至 GPU
inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True).to(model.device)
# 正向传递
outputs = model(**inputs)
loss = output.loss
# 反向传递
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Loss: {loss.item()}") # 可选择打印损失以进行监控
由于预训练模型只需进行微调,不需要初始训练,因此可以显著减少训练所需的时间。
改进模型准确性
可以通过多种方式提高此版本的正确性。这些包括微调结构、迁移学习和增强统计数据。
1. 数据增强
如果通过统计增强添加更多信息,版本将更加准确,因为这会使版本面临更大的变化。
from nlpaug.augmenter.word import SynonymAug
# 同义词增强
aug = SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("该模型经过训练可以生成文本。")
print(augmented_text)
输出
['该模型经过训练可以生成文本。']
数据增强可以使您的 Llama 模型更具弹性,因为您的训练数据集增加了多样性。
2.迁移学习
迁移学习使您能够利用在相关任务上训练的模型,从而使您无需大量数据即可获得准确性。
from transformers import LlamaForSequenceClassification
from huggingface_hub import login
login(token='YOUR_HUGGING_FACE_TOKEN')
# 加载预先训练的 Llama 模型并在分类任务上进行微调
model = LlamaForSequenceClassification.from_pretrained("meta-Llama/Llama-2-7b-chat-hf", num_labels=2)
model.train()
# 微调循环
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
这将使 Llama 模型能够专注于重用和调整其知识以适应您的特定任务,即使其更加准确。
总结
这是迄今为止在优化的 Llama 模型中获得高效和有效的机器学习解决方案的最关键部署之一。参数调整、梯度累积、修剪、量化和分布式训练等技术极大地提高了性能并减少了训练所需的时间。通过数据增强和迁移学习提高准确性增强了模型的稳健性和可靠性。


