分布式系统中的查询优化
本章讨论分布式数据库系统中的查询优化。
分布式查询处理架构
在分布式数据库系统中,处理查询包括全局和本地级别的优化。 查询进入客户端或控制站点的数据库系统。 在这里,用户得到验证,查询在全局级别得到检查、翻译和优化。
该架构可以表示为 −
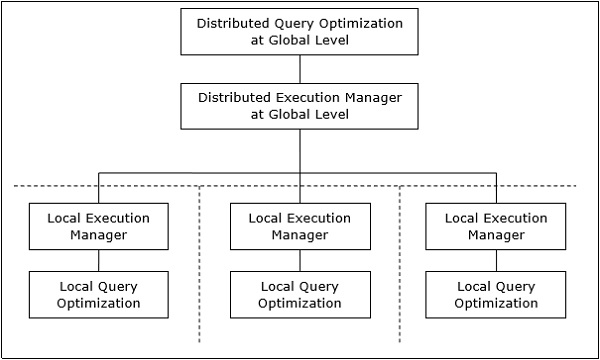
将全局查询映射到本地查询
将全局查询映射到本地查询的过程可以如下实现 −
全局查询所需的表具有分布在多个站点上的片段。 本地数据库仅包含有关本地数据的信息。 控制站点使用全局数据字典来收集有关分布的信息,并从片段中重建全局视图。
如果没有复制,全局优化器将在存储片段的站点上运行本地查询。 如果存在复制,全局优化器会根据通信成本、工作负载和服务器速度来选择站点。
全局优化器生成分布式执行计划,以便跨站点发生最少的数据传输。 该计划规定了片段的位置、查询步骤需要执行的顺序以及传输中间结果所涉及的过程。
本地查询由本地数据库服务器优化。 最后,对于水平分片,通过union操作,对于垂直分片,通过join操作,将本地查询结果合并在一起。
例如,让我们考虑以下项目架构根据城市进行水平分段。
PROJECT
| PId | City | Department | Status |
假设有一个查询来检索所有状态为"ongoing(正在进行)"的项目的详细信息。
全局查询将是 &inus;
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
在新德里的服务器中查询将是 −
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
加尔各答服务器中的查询将是 −
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
海得拉巴服务器中的查询将是 −
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
为了得到整体结果,我们需要将三个查询的结果合并起来,如下所示 −
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
分布式查询优化
分布式查询优化需要评估大量查询树,每个查询树都会生成查询所需的结果。 这主要是由于存在大量重复和碎片数据。 因此,我们的目标是找到最优解,而不是最佳解。
分布式查询优化的主要问题是 −
- 分布式系统中资源的优化利用。
- 查询事务。
- 减少查询的解决方案空间。
分布式系统资源的优化利用
分布式系统在各个站点具有许多数据库服务器来执行与查询相关的操作。 以下是最佳资源利用的方法−
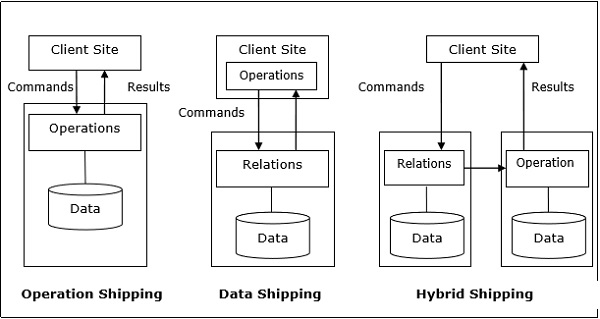
传输操作 − 在传输操作中,操作在存储数据的站点而不是在客户端站点运行。 然后将结果传输到客户端站点。 这适用于操作数在同一站点可用的操作。 示例:选择和项目操作。
数据传输 − 在数据传输中,数据片段被传输到数据库服务器,并在数据库服务器上执行操作。 这用于操作数分布在不同站点的操作。 这也适用于通信成本较低且本地处理器比客户端服务器慢得多的系统。
混合传输 − 这是数据和操作传输的结合。 在这里,数据片段被传输到运行操作的高速处理器。 然后将结果发送到客户端站点。
查询事务
在分布式数据库系统的查询事务算法中,分布式查询的控制/客户端站点称为买方,执行本地查询的站点称为卖方。 买方制定了多种选择来选择卖方并重建全局结果。 买方的目标是实现成本最优。
该算法从买方将子查询分配给卖方网站开始。 最优计划是根据卖家提出的本地优化查询计划结合重构最终结果的通信成本创建的。 一旦制定了全局最优计划,就执行查询。
减少查询的解决方案空间
最佳解决方案通常涉及减少解决方案空间,从而降低查询和数据传输的成本。 这可以通过一组启发式规则来实现,就像集中式系统中的启发式规则一样。
以下是一些规则 −
尽早执行选择和投影操作。 这减少了通信网络上的数据流。
通过消除与特定站点不相关的选择条件来简化水平片段的操作。
如果连接和并集操作包含位于多个站点的碎片,请将碎片数据传输到大部分数据所在的站点并在那里执行操作。
使用半连接操作来限定要连接的元组。 这减少了数据传输量,从而降低了通信成本。
合并分布式查询树中的公共叶子和子树。

