Apache Flink - 架构
Apache Flink 工作在 Kappa 架构上。 Kappa架构有一个单一的处理器——流,它将所有输入视为流,流引擎实时处理数据。 kappa架构中的批量数据是流式传输的一个特例。
下图显示了 Apache Flink 架构。
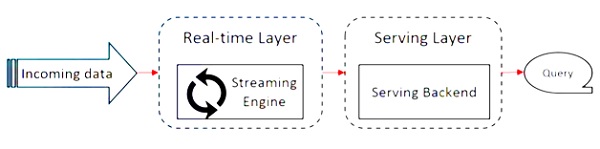
Kappa 架构的关键思想是通过单个流处理引擎处理批量和实时数据。
大多数大数据框架都在 Lambda 架构上运行,该架构具有用于批处理和流数据的单独处理器。 在 Lambda 架构中,批处理视图和流视图有单独的代码库。 为了查询和获取结果,需要合并代码库。 不维护单独的代码库/视图并将它们合并是一种灾难,但 Kappa 架构解决了这个问题,因为它只有一个视图 − 实时,因此不需要合并代码库。
这并不意味着 Kappa 架构取代了 Lambda 架构,它完全取决于用例和应用程序来决定哪种架构更可取。
下图展示了 Apache Flink 作业执行架构。
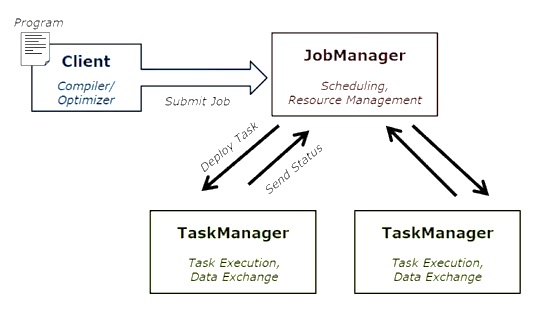
程序
它是一段代码,您在 Flink 集群上运行。
客户端
它负责获取代码(程序)并构建作业数据流图,然后将其传递给JobManager。 它还检索作业结果。
作业管理器
从Client接收到Job Dataflow Graph后,负责创建执行图。 它将作业分配给集群中的TaskManager并监督作业的执行。
任务管理器
它负责执行JobManager分配的所有任务。 所有任务管理器以指定的并行度在各自的插槽中运行任务。 它负责将任务的状态发送给JobManager。
Apache Flink 的功能
Apache Flink的特点如下 −
它有一个流处理器,可以运行批处理和流程序。
它可以以闪电般的速度处理数据。
API 可用于 Java、Scala 和 Python。
提供了所有常用操作的API,方便程序员使用。
以低延迟(纳秒)和高吞吐量处理数据。
它是容错的。 如果节点、应用程序或硬件出现故障,不会影响集群。
可以轻松与Apache Hadoop、Apache MapReduce、Apache Spark、HBase等大数据工具集成。
可以自定义内存管理以实现更好的计算。
它具有高度可扩展性,可以扩展到集群中的数千个节点。
Apache Flink 中的窗口化非常灵活。
提供图形处理、机器学习、复杂事件处理库。

