机器学习中的 Python 多项式回归
简介
多项式回归是一种线性回归,在多项式回归中,因变量 Y 和自变量 X 之间的联系被建模为多项式的 n 次方。为了使用数据点绘制最佳线,必须这样做。让我们在本文中进一步探索多项式回归。
多项式回归
多元线性回归模型的罕见实例之一是多项式回归。换句话说,当因变量和自变量彼此之间存在曲线连接时,它是一种线性回归。在数据中,拟合多项式连接。
此外,通过合并几个多项式部分,许多线性回归方程被转换为多项式回归方程。
在多项式回归中,独立变量 x 和因变量 y 之间的关系被建模为 n 次多项式。通过多项式回归可以拟合 x 的值和 y 的相关条件均值之间的非线性关系,该关系由符号 E(y |x) 给出。
多项式回归的必要性
下面列出了一些指定多项式回归要求的标准。
如果将线性模型用于线性数据库,就像简单线性回归的情况一样,会产生良好的结果。但是,如果将此模型应用于不做任何调整的非线性数据集,则会计算出显著的输出。这些会导致错误率增加、准确率下降和损失函数增加。
当数据点以非线性方式排列时,需要使用多项式回归。
如果有非线性模型可用并且我们尝试覆盖它,则线性模型不会覆盖任何数据点。为了保证覆盖所有数据点,我们采用多项式模型。然而,在使用多项式模型时,曲线而不是直线对于大多数数据点来说效果会更好。
如果我们尝试将线性模型拟合到曲线数据,则预测器(X 轴)上的残差(Y 轴)散点图将显示中间内部的许多正残差区域。因此,在这种情况下它是不合适的。
多项式回归应用
基本上,它们用于定义或枚举非线性现象。
组织生长率。
流行病的进展。
湖泊沉积物中的碳同位素分布。
对因变量 y 相对于自变量 x 值的估计回报进行建模是回归分析的基本目的。我们在简单回归中使用了下面的方程
y = a + bx + e
这里,因变量是 y,还有自变量 a、b 和 e。
多项式回归类型
由于多项式方程的次数没有上限,可以达到第 n 个数字,因此存在许多类型的多项式回归。例如,多项式方程的二次方程在口语中通常表示为二次方程。如所示,这个次数有效到第 n 个数字,我们可以自由地推导出我们需要或想要的相当多的方程。因此,多项式回归通常分为以下几类。
当次数为 1 时,为线性。
方程的二次次数为 2。
根据使用的次数,三次方继续。
例如,当根据合成发生的温度检查化学合成的输出时,这种线性模型通常不起作用。在这种情况下,我们采用二次模型。
y = a+b1x+b2+b2+e
这里,错误率为 e,y 截距为 a,y 是 x 的因变量。
多项式回归的 Python 实现
步骤 1 - 导入数据集和库
导入多项式回归分析所需的库以及数据集。
# 导入库 import numpy as nm import matplotlib.pyplot as mplt import pandas as ps # 导入数据集 data = ps.read_csv('data.csv') data
输出
sno Temperature Pressure 0 1 0 0.0002 1 2 20 0.0012 2 3 40 0.0060 3 4 60 0.0300 4 5 80 0.0900 5 6 100 0.2700
步骤 2 − 在第二步中,数据集被拆分为两个部分。
将数据集拆分为 X 和 y 部分。X 将包含列 1 和列 2。这两列将位于 y 列。
X = data.iloc[:, 1:2].values y = data.iloc[:, 2].values
步骤 3 - 使用线性回归拟合数据集
拟合线性回归模型的两个组成部分。
from sklearn.linear_model import LinearRegressiondata line2 = LinearRegressiondata() line2.fit(X, y)
步骤 4 - 多项式回归拟合数据集
X 和 Y 是多项式回归模型拟合的两个分量。
from sklearn.preprocessing import PolynomialFeaturesdata poly = PolynomialFeaturesdata(degree = 4) X_polyn = polyn.fit_transform(X) polyn.fit(X_polyn, y) line3 = LinearRegressiondata() line3.fit(X_polyn, y)
步骤 5 - 在此阶段,我们利用散点图来可视化线性回归的结果。
mplt.scatter(X, y, color = 'blue') mplt.plot(X, lin.predict(X), color = 'red') mplt.title('Linear Regression') mplt.xlabel('Temperature') mplt.ylabel('Pressure') mplt.show()
输出
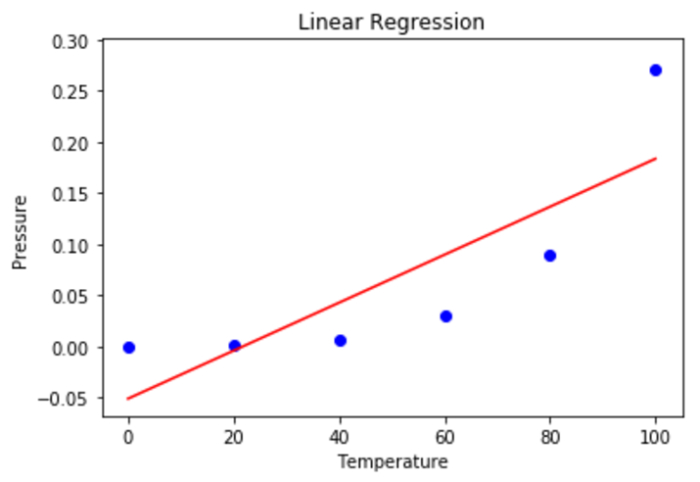
步骤 6 - 使用散点图显示多项式回归结果。
mplt.scatter(X, y, color = 'blue') mplt.plot(X, lin2.predict(polyn.fit_transform(X)), color = 'red') mplt.title('Polynomial Regression') mplt.xlabel('Temperature') mplt.ylabel('Pressure') mplt.show()
输出
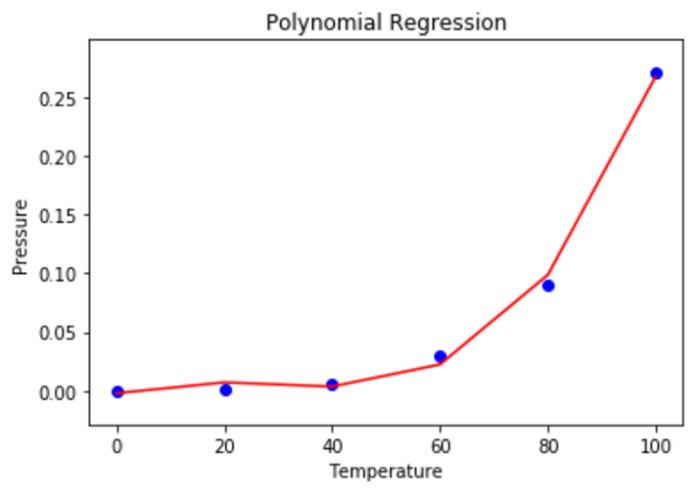
步骤 7 - 使用线性和多项式回归来预测未来结果。需要注意的是,NumPy 2D 数组必须包含输入变量。
线性回归
predic = 110.0 predicdarray = nm.array([[predic]]) line2.predict(predicdarray)
输出
Array([0.20657625])
多项式回归
Predic2 = 110.0 predic2array = nm.array([[predic2]]) line3.predicdict(polyn.fit_transform(predicd2array))
输出
Array([0.43298445])
优点
它能够执行各种各样的操作任务。
一般来说,多项式适合大范围的曲面。
多项式最能表示变量之间的关系。
缺点
这些对偏差极为敏感。
非线性分析的结果可能会受到一个或两个变量存在的显著影响。
此外,与线性回归相比,遗憾的是,可用于发现非线性回归中偏差的模型验证技术较少。
结论
在本文中,我们了解了多项式回归背后的理论。我们学习了多项式回归的实现。
将此模型应用于真实数据集后,我们可以看到其图表并利用它来预测事物。我们希望本次课程有益,并且我们现在可以自信地将这些知识应用于其他数据集。


