如何使用 TensorFlow 在 Auto MPG 上构建顺序模型?
Tensorflow 是 Google 提供的机器学习框架。它是一个开源框架,与 Python 结合使用,用于实现算法、深度学习应用程序等等。它用于研究和生产目的。Tensor 是 TensorFlow 中使用的数据结构。它有助于连接流程图中的边缘。此流程图称为"数据流图"。张量不过是多维数组或列表。可以使用三个主要属性来识别它们 −
等级− 它说明了张量的维数。它可以理解为张量的顺序或已定义的张量中的维数。
类型 −它说明了与张量元素相关的数据类型。它可以是一维、二维或 n 维张量。
形状 − 它是行数和列数的总和。
可以使用以下代码行在 Windows 上安装 ‘tensorflow’ 包 −
pip install tensorflow
回归问题的目的是预测连续或离散变量的输出,例如价格、概率、是否会下雨等等。
我们使用的数据集称为 ‘Auto MPG’ 数据集。它包含 20 世纪 70 年代和 80 年代汽车的燃油效率。它包括重量、马力、排量等属性。为此,我们需要预测特定车辆的燃油效率。
顺序模型是一种基于层堆栈的模型。
我们使用 Google Colaboratory 运行以下代码。Google Colab 或 Colaboratory 有助于在浏览器上运行 Python 代码,并且不需要任何配置,并且可以免费访问 GPU(图形处理单元)。Colaboratory 是在 Jupyter Notebook 之上构建的。以下是代码片段 −
示例
print("A sequential model is being built with 1 dense layer")
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
print("Predictions are being made ")
linear_model.predict(train_features[:10])
linear_model.layers[1].kernel
print("Model is being compiled")
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
print("The model is being fit to the data")
history = linear_model.fit(
train_features, train_labels,
epochs=150,
verbose=0,
validation_split = 0.25)
print("The predicted values are being plotted")
plot_loss(history)
print("The predicted results are being evaluated")
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
代码来源 −https://www.tensorflow.org/tutorials/keras/regression
输出
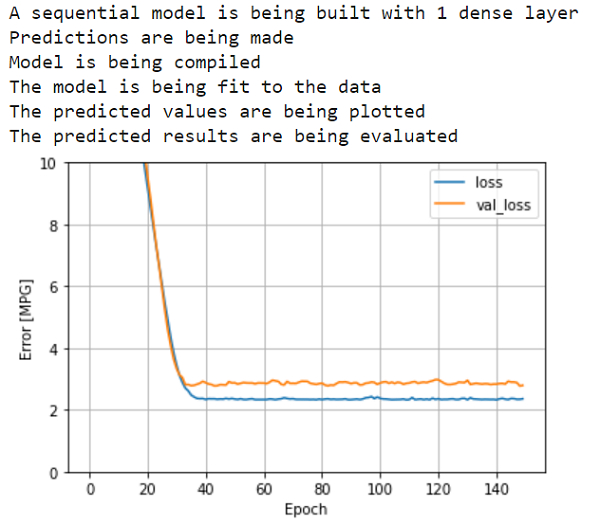
解释
使用 keras API 构建顺序架构模型。
对‘MPG’进行预测。
线性回归的一般格式为 y= mx + b。
一旦做出预测,就会编译此模型。
接下来,将模型拟合到数据中,其中定义了训练步骤的数量。
先前预测的值绘制在控制台上。


