突出显示 Pandas Dataframe 中的 NaN 值
处理不完整或缺失的数据是数据分析中的常见挑战,解决此问题的第一步是识别数据结构(如 Pandas Dataframe)中的 nan(缺失)值。在 Pandas DataFrame 中,这些缺失值通常表示为 NaN(非数字)值,这可能由于各种原因而发生,例如数据输入、提取或处理过程中的错误。但是,检测和精确定位这些 NaN 值可能非常困难,尤其是在处理大量数据集时。
幸运的是,Pandas 提供了一系列有效的技术来检测和管理缺失值。本文将探讨在 Pandas DataFrame 中识别 NaN 值的多种方法,包括利用 isna()、notna() 和 info() 等内置函数,以及采用热图可视化等高级方法对缺失数据进行处理。
如何突出显示 Pandas DataFrame 中的 NaN 值?
要识别 Pandas DataFrame 中的 NaN 值,我们可以通过内置函数和高级方法采用各种方法。让我们深入了解这些技术的细节 −
内置函数
方法 1:isna()
此函数返回与输入形状相同的 DataFrame,其中每个元素如果是 NaN 值则为 True,否则为 False。您可以使用此函数来识别缺失值的位置。
isna() 函数返回与输入形状相同的 DataFrame,其中每个元素如果是 NaN 值则标记为 True,否则标记为 False。您可以使用此函数来识别缺失值的位置。
示例
import pandas as pd
# 创建示例 DataFrame
data = {'Column1': [1, 2, None, 4, 5], 'Column2': [6, None, 8, 9, 10]}
df = pd.DataFrame(data)
# 使用 isna() 识别 NaN 值
nan_df = df.isna()
print(nan_df)
输出
Column1 Column2
0 False False
1 False True
2 True False
3 False False
4 False False
在生成的 DataFrame 中,True 值表示存在缺失值,而 False 值表示非缺失值或 NaN。
方法 2:notna()
与 isna() 类似,此函数也返回具有相同形状的 DataFrame。但是,如果每个元素不是 NaN 值,它会将其标记为 True,如果是缺失值,则会将其标记为 False。
要应用 notna(),您只需在 DataFrame 或特定列上调用它即可。生成的 DataFrame 将具有与原始 DataFrame 相同的形状,其中 True 值表示非缺失值,False 值表示缺失值。
示例
import pandas as pd
# 创建示例 DataFrame
data = {'Column1': [1, 2, None, 4, 5], 'Column2': [6, None, 8, 9, 10]}
df = pd.DataFrame(data)
# 使用 notna() 识别非 NaN 值
notnan_df = df.notna()
print(notnan_df)
输出
Column1 Column2 0 True True 1 True False 2 False True 3 True True 4 True True
在生成的 DataFrame 中,True 值表示存在非缺失值,而 False 值表示缺失值或 NaN。此方法可用于过滤、条件操作或检查 Pandas DataFrame 中数据的完整性。
方法 3:info()
此方法提供 DataFrame 的摘要,包括每列中非空值的数量。通过检查此摘要,您可以轻松识别具有缺失值的列。非空值数量较少的列表示存在 NaN 值。
示例
import pandas as pd
# 创建示例 DataFrame
data = {'Column1': [1, 2, None, 4, 5], 'Column2': [6, None, 8, 9, 10]}
df = pd.DataFrame(data)
# 使用 info() 获取摘要
df.info()
输出
RangeIndex: 5 entries, 0 to 4 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Column1 4 non-null float64 1 Column2 4 non-null float64 dtypes: float64(2) memory usage: 208.0 bytes
输出提供了有关 DataFrame 的信息,例如总行数 (5)、列名 ('Column1' 和 'Column2')、非空值计数 (两列均为 4) 以及数据类型 (float64)。此摘要通过将非空计数与总行数进行比较,有助于识别具有缺失值的列。
高级方法
方法 4:热图可视化
通过使用热图可视化缺失数据,您可以全面了解整个 DataFrame 中缺失值的分布情况。热图使用颜色渐变来表示每个单元格中 NaN 值的存在与否,从而让您能够识别缺失数据的模式或集群。
示例
import pandas as pd
# 创建示例 DataFrame
data = {'Column1': [1, 2, None, 4, 5], 'Column2': [6, None, 8, 9, 10]}
df = pd.DataFrame(data)
import matplotlib.pyplot as plt
import seaborn as sns
# 创建缺失值热图
sns.heatmap(df.isna(), cmap='viridis')
plt.show()
输出
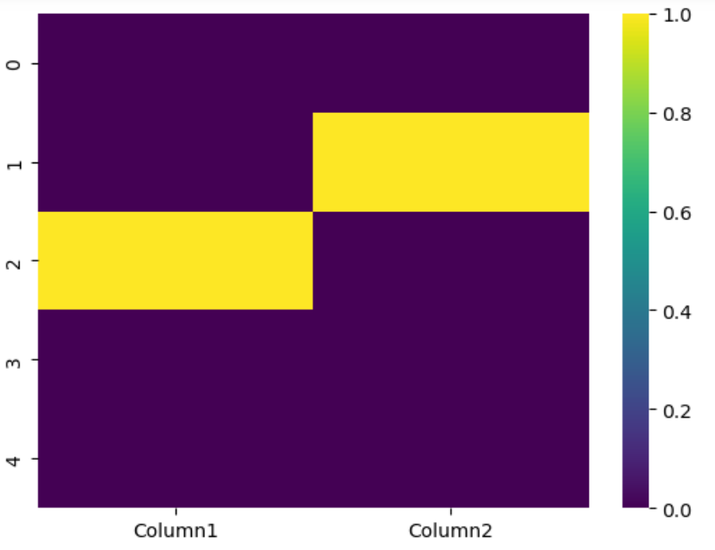
生成的热图可视化了 DataFrame 中缺失值的分布。黄色单元格表示存在缺失值 (NaN),可让您识别列和行中缺失数据的模式或群集。此可视化有助于了解数据集中缺失值的范围和位置。
结论
总之,识别和突出显示 Pandas DataFrame 中的 NaN 值对于数据分析至关重要。通过利用 isna() 和 notna() 等内置函数以及热图可视化等高级方法,我们可以有效地检测和可视化缺失数据,从而实现准确的数据处理和明智的决策。


