第一范式 (1NF)
dbmsdatabasemysql
什么是 1NF
1NF 是 DBMS 中的第一范式,应用于非规范化表以使其规范化。非规范化表存在以下问题,我们需要避免这些问题才能获得完美的数据库设计 −
非规范化表的问题
数据冗余
多次存储相同的数据项称为数据冗余。
让我们看一个例子 −
我们有一个 <Employee> 表,其中有一个字段用于存储员工的当前地址。其中一些员工由公司提供住所;因此,他们有相同的地址。该地址将在数据库中重复 −
表 1.1
| EmpID | EmpName | EmpAddress |
| 001 | Amit | 11, VA Street, New York |
| 002 | Tom | 11, VA Street, New York |
| 003 | David | 11, VA Street, New York |
| 004 | Steve | 13, HG Block, Philadelphia |
| 005 | Jeff | 13, HG Block, Philadelphia |
要解决这个问题,请将员工地址存储在单独的表中,并指向 <Employee> 表。
更新异常
当您在更新表时遇到问题时会发生这种情况。
让我们看一个例子 −
表 1.2
| EmpID | EmpName | EmpAddress | EmpDept |
| 001 | Amit | 11, VA Street, New York | A |
| 002 | Tom | 11, VA Street, New York | B |
| 003 | Tom | 11, VA Street, New York | C |
| 004 | Steve | 13, HG Block, Philadelphia | D |
| 005 | Jeff | 27, ZR Block, Virginia | E |
如果我们需要更新来自两个部门的员工 Tom 的地址,那么我们需要更新两行。如果我们只更新一行,那么 Tom 就会有两个不同的地址,从而导致数据不一致。
删除异常
假设公司决定关闭部门 D,那么删除行也会导致删除员工 Steve 的数据。
插入异常
当您尝试在一条不存在的记录中插入数据时,就会发生这种情况。
规范化可以消除上述所有问题/异常,并为您提供数据库管理员喜爱的规范化完美数据库设计。
让我们看看如何使用第一范式 (1NF) 规范化数据
为什么是 INF
第一范式 (1 INF) 有助于消除数据库的数据冗余问题和异常,如上一节所示。 1NF 中的所有属性都应具有原子域。如果不是原子的,那么您的数据库设计就不好。这是规范化的第一步。
因此,表格要采用规范化形式,最重要的规则是它应该只具有原子值。
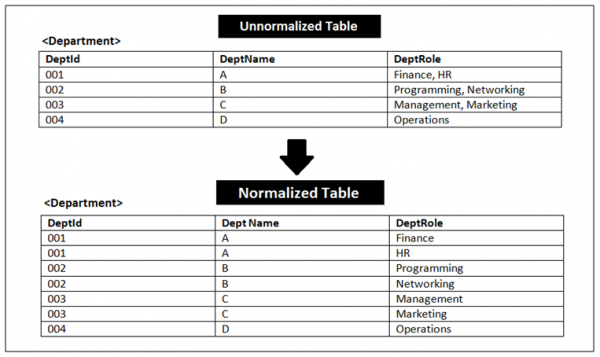
示例
以下示例有一个表格,其中除 DeptRole 列外,每列都由原子值组成。因此,DeptRole 列违反了部门 A、B 和 C 的原子值规则。
表 1.3
| DeptId | DeptName | DeptRole |
| 001 | A | Finance, HR |
| 002 | B | Programming, Networking |
| 003 | C | Management, Marketing |
| 004 | D | Operations |
Let us now correct it and convert to 1NF:
| DeptId | Dept Name | DeptRole |
| 001 | A | Finance |
| 001 | A | HR |
| 002 | B | Programming |
| 002 | B | Networking |
| 003 | C | Management |
| 003 | C | Marketing |
| 004 | D | Operations |
现在上面的表格是 1NF,每一列都有原子值,如下面的屏幕截图所示 −