DBMS 中的死锁
当两个或多个进程需要某些资源来完成其执行,而这些资源由另一个进程持有时,就会发生死锁。 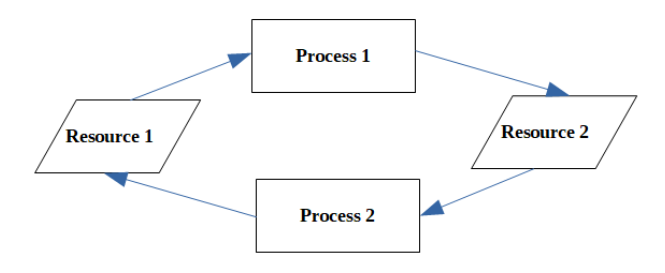
在上图中,进程 1 拥有资源 1,需要资源 2。同样,进程 2 拥有资源 2,需要资源 1。每个进程都需要对方的资源来完成,但它们都不愿意放弃自己的资源。因此,进程 1 和进程 2 处于死锁状态。
科夫曼条件
只有当四个科夫曼条件成立时,才会发生死锁。这些条件不一定是相互排斥的。它们是:
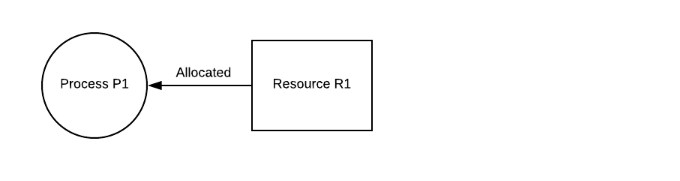
相互排斥
应该有一个资源一次只能由一个进程持有。在下图中,资源 R1 有一个实例,并且仅由进程 P1 持有。
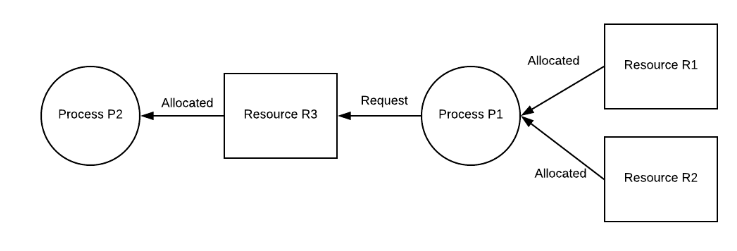
持有并等待
一个进程可以持有多个资源,并且仍然可以从持有这些资源的其他进程请求更多资源。在下图中,进程 P1 拥有资源 R1 和 R2,并请求进程 P2 拥有的资源 R3。
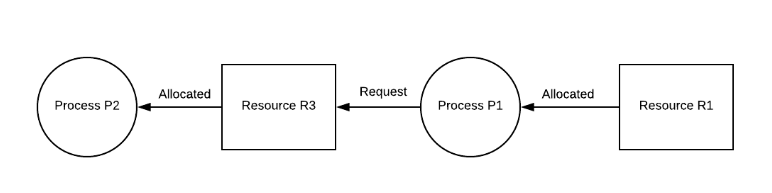
无抢占
资源不能被强制从进程中抢占。进程只能自愿释放资源。在下图中,进程 P1 不能从进程 P2 中抢占资源 R3。只有当 P2 在执行完成后自愿放弃它时,它才会被释放。
循环等待
一个进程正在等待第二个进程持有的资源,第二个进程正在等待第三个进程持有的资源,依此类推,直到最后一个进程正在等待第一个进程持有的资源。这形成了一个循环链。例如:进程 P1 被分配资源 R1,它正在请求资源 R2。同样,进程 P2 被分配资源 R2,它正在请求资源 R1。这形成了一个循环等待循环。
一个进程正在等待第二个进程持有的资源,第二个进程正在等待第三个进程持有的资源,依此类推,直到最后一个进程正在等待第一个进程持有的资源。这形成了一个循环链。例如:进程 P1 被分配了资源 R1,它正在请求资源 R2。同样,进程 P2 被分配了资源 R2,它正在请求资源 R1。这形成了一个循环等待循环。
死锁检测
资源调度程序可以检测到死锁,因为它会跟踪分配给不同进程的所有资源。检测到死锁后,可以使用以下方法解决:
- 终止死锁中涉及的所有进程。这不是一个好方法,因为进程取得的所有进展都被破坏了。
- 可以抢占某些进程的资源并将其提供给其他进程,直到解决死锁为止。
死锁预防
在死锁发生之前防止死锁至关重要。因此,系统会在执行每个事务之前严格检查它,以确保它不会导致死锁。如果事务有可能导致死锁的可能,则绝不允许执行。
有些死锁预防方案使用时间戳来确保不会发生死锁。这些是 −
- 等待 - 死亡方案
在等待 - 死亡方案中,如果事务 T1 请求事务 T2 持有的资源,则可能出现以下两种情况之一:
- TS(T1) < TS(T2) - 如果 T1 比 T2 更老,即 T1 比 T2 更早进入系统,则允许等待 T2 完成执行后将释放的资源。
TS(T1) > TS(T2) - 如果 T1 比 T2 年轻,即 T1 在 T2 之后进入系统,则 T1 被终止。稍后将使用相同的时间戳重新启动。
- 伤口 - 等待方案
在伤口 - 等待方案中,如果事务 T1 请求事务 T2 持有的资源,则可能会发生以下两种情况之一:
- TS(T1) < TS(T2) - 如果 T1 比 T2 更早,即 T1 比 T2 更早进入系统,则允许回滚 T2 或伤口 T2。然后 T1 获取资源并完成其执行。T2 稍后会以相同的时间戳重新启动。
TS(T1) > TS(T2) - 如果 T1 比 T2 年轻,即 T1 在 T2 之后进入系统,则允许等待 T2 完成执行后可用的资源。
避免死锁
最好避免死锁,而不是在死锁发生后采取措施。等待图可用于避免死锁。但这仅适用于较小的数据库,因为在较大的数据库中它会变得非常复杂。
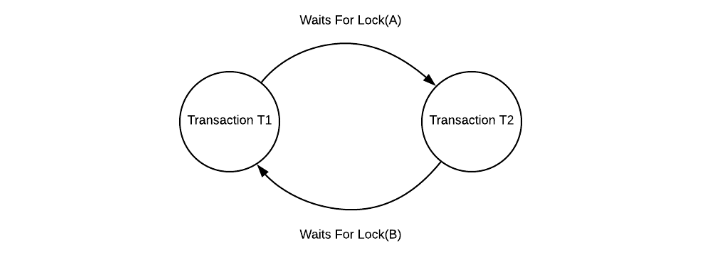
等待图
等待图显示资源和事务之间的关系。如果事务请求资源或已经拥有资源,则它在等待图上显示为一条边。如果等待图包含一个循环,则系统中可能存在死锁,否则不存在。
忽略死锁 - 鸵鸟算法
鸵鸟算法意味着死锁被忽略,并且假定它永远不会发生。这样做是因为在某些系统中,处理死锁的成本比简单地忽略它要高得多,因为它很少发生。因此,简单地假设死锁永远不会发生,并且如果偶然发生,系统就会重新启动。


